











Hỗ trợ tư vấn
Tư vấn - Giải đáp - Hỗ trợ đặt tài liệu
Hàm ImportXML sẽ giúp bạn lấy dữ liệu từ website vào Google Sheets. Dưới đây là cách dùng hàm ImportXML trong Google Sheets.
Microsoft Excel không còn là ứng dụng bảng tính hữu ích nhất bởi hiện người dùng đã có nhiều lựa chọn thay thế khác, thậm chí còn miễn phí. Google Sheets là một trong số đó.
Về cơ bản, Google Sheets không khác nhiều so với Excel. Ngay từ lần đầu tiên sử dụng, bạn sẽ thấy giao diện của nó khá quen thuộc với các công cụ căn chỉnh, định dạng ô, sao chép và hợp nhất dòng… Google Sheets cũng hỗ trợ hàm tính với nhiều phép tính thông dụng như cộng/trừ/nhân/chia dữ liệu trong ô liên quan. Nếu biết dùng Excel, không khó để bạn dùng Google Sheets.
Điểm đặc biệt ở phần mềm bảng tính này là bạn không cần phải cài đặt, chỉ cần có tài khoản Google là dùng được ngay. Chính vì hoạt động dựa trên trình duyệt, Google Sheets có thể tự động cập nhật thông tin khi không có mặt bạn. Bạn có thể chia sẻ bảng tính với người khác, nhập nguồn để Google Sheets lấy dữ liệu liên quan khi có thay đổi. Chỉ cần vài thiết lập đơn giản, Sheets sẽ giúp bạn tiết kiệm thời gian cũng như công sức xử lý bảng tính đáng kể.
Thế nhưng nếu muốn tải số lượng lớn dữ liệu trên web, chẳng hạn như sao chép thông tin từ một bảng online (danh sách sự kiện, bảng thống kê hay địa chỉ email nằm rải rác trên web), việc sao chép & dán chúng thật tốn thời gian và công sức phải không? Google Sheets có một lựa chọn tốt hơn cho bạn.
Bạn có thể nhập dữ liệu từ trang web bất kỳ bằng một hàm nhỏ nhưng có võ mang tên ImportXML. Một khi đã nắm vững hàm ImportXML Google Sheets, công việc thu thập hàng loạt dữ liệu trên web trở nên vô cùng đơn giản.
Ngôn ngữ đánh dấu XML chỉ định các bộ dữ liệu trong một trang web. Về bản chất, bất kỳ bộ <something> và </something> - các khối xây dựng của mã nguồn web hay một tập hợp dữ liệu nhất định sẽ nằm bên trong chúng. Mã nguồn của web sẽ có một số text trong thẻ <p>aragraph - đoạn văn, đôi khi chứa <b>old - chữ in đậm và có thể cả <a>a link - liên kết (được theo sau bởi </a></b>.</p></body> để đóng toàn bộ thẻ).
Hàm ImportXML của Google Sheets có thể tìm một bộ dữ liệu XML nào đó và sao chép dữ liệu bên ngoài nó. Ở ví dụ trên, nếu muốn lấy toàn bộ liên kết trên trang, chúng ta cần yêu cầu hàm ImportXML nhập toàn bộ thông tin trong tag <a></a>. Nếu muốn toàn bộ text của một web, bạn có thể bắt đầu bằng cách lấy mọi thứ trong <body></body> hoặc mỗi phiên bản của <p></p>, rồi xóa dữ liệu ở các giai đoạn sau.
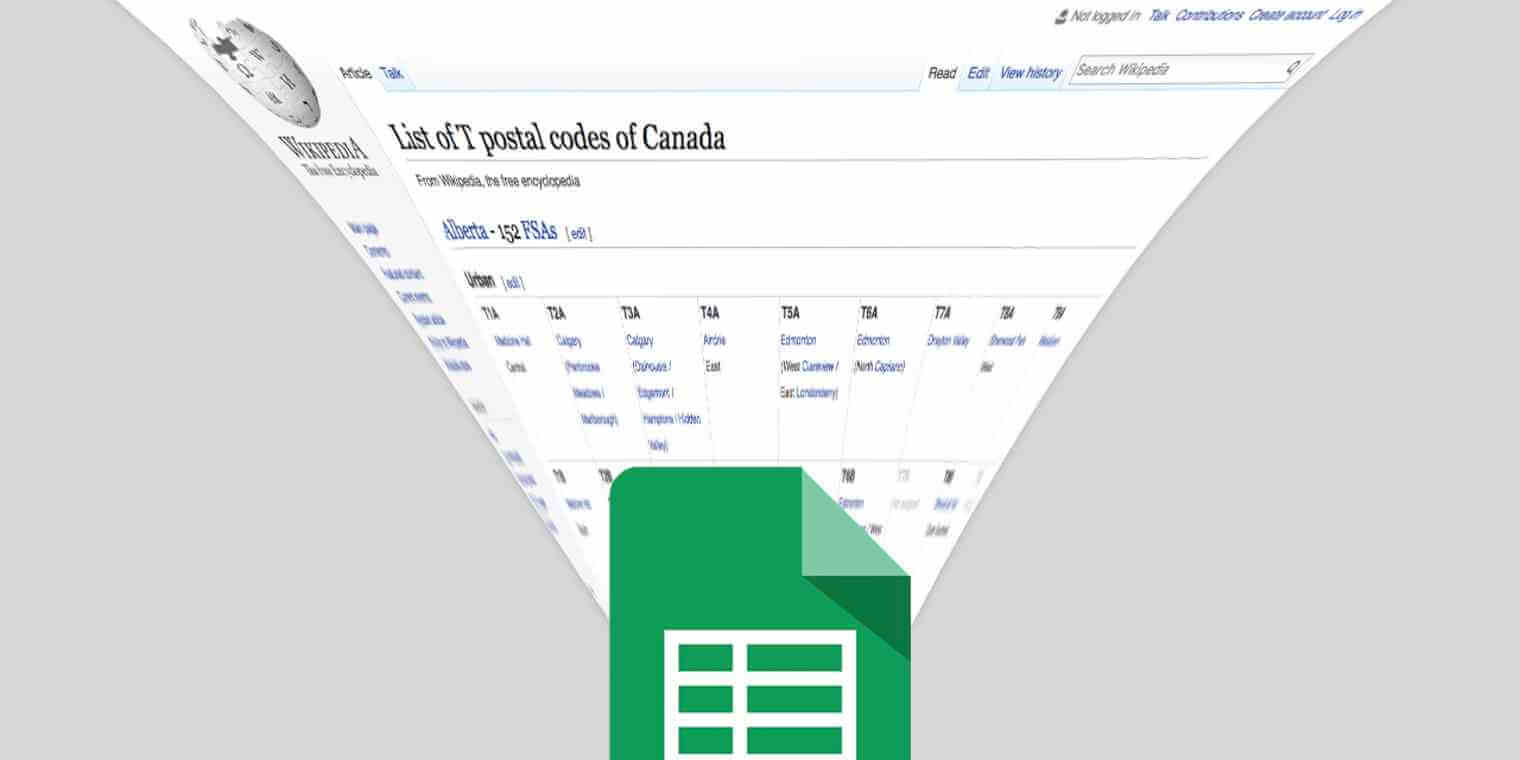
Bảng biểu trong Wikipedia là bài luyện tập ImportXML tuyệt vời. Bài viết sẽ lấy ví dụ tải toàn bộ mã bưu điện ở Edmonton, Alberta. Tìm danh sách mã bưu điện của Canada bắt đầu bằng chữ T. Mở trang đó trong cửa sổ trình duyệt mới để bắt đầu.
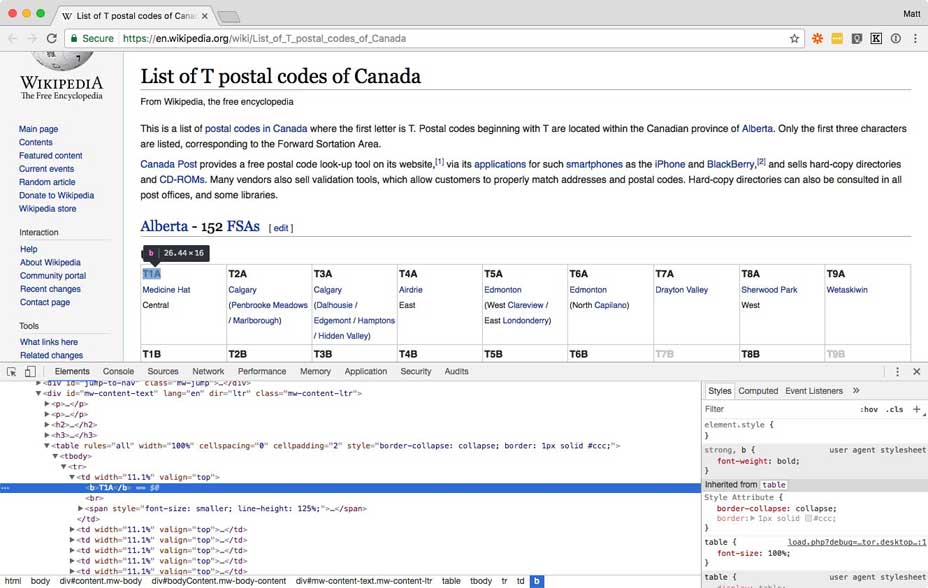
Chọn một mã bưu điện, click chuột phải vào nó và chọn Inspect để mở công cụ trình duyệt xem mã nguồn trang. Bạn sẽ thấy mỗi mã nguồn trang nằm trong một tag (xác định một ô trong bảng). Sau đó, bài viết sẽ nhập toàn bộ tag TD chứa từ Edmonton trong chúng.
Tạo một bảng tính Google Sheet trống mới. Bài viết sẽ lấy toàn bộ nội dung tag TD, bao gồm <span> và liên kết bằng cách xác định dữ liệu muốn dùng cú pháp Xpath. ImportXML lấy URL và tag bạn đang tìm làm đối số để nhập vào Google Sheets.
=importxml("https://en.wikipedia.org/wiki/List_of_T_postal_codes_of_Canada", "//td")
Bạn sẽ nhận được kết quả như sau:
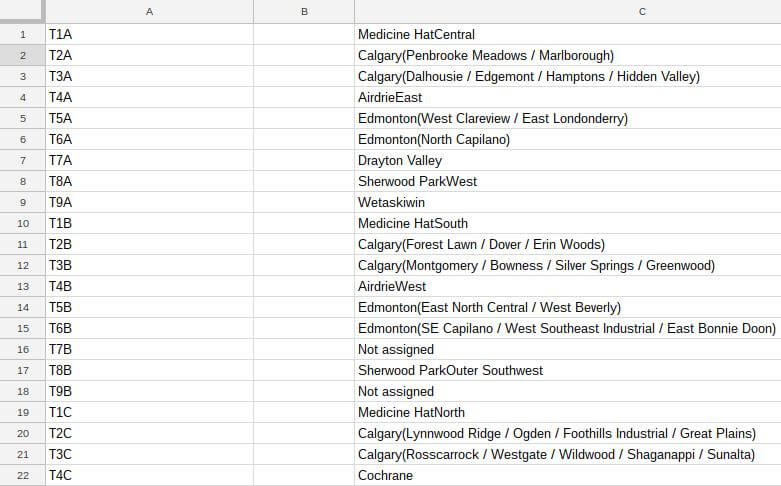
Quay lại nguồn trang, chúng ta sẽ thấy mã bưu chính được in đậm trong thẻ <b></b>, tên thành phố liên kết tới các bài báo Wikipedia nằm trong <a></a>. Giờ hãy thử chỉ lấy liên kết trong mỗi ô thành phố lớn và loại bỏ các liên kết khác (khu phố). Chỉnh sửa chúng thành hai lệnh trọng cột A và B:
=importxml("https://en.wikipedia.org/wiki/List_of_T_postal_codes_of_Canada", "//td/span/a[1]")
=importxml("https://en.wikipedia.org/wiki/List_of_T_postal_codes_of_Canada", "//td/b[1]")
Bạn cần tinh chỉnh kết quả một chút:
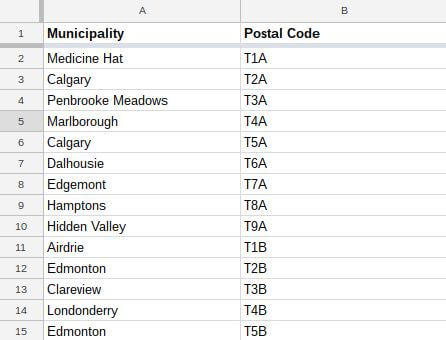
Hành động này giúp bạn hiểu cách cú pháp truy vấn XPath hoạt động: một thẻ chỉ cung cấp phiên bản đầu tiên của <tag> trong <parent tag>. Vì thế, td/span/a[1] cho bạn liên kết đầu tiên trong <span> ở mỗi <td>. Tương tự như vậy, td/b[1] cho bạn text in đậm trước tiên trong mỗi <td> hoặc chỉ mã bưu điện ở trường hợp này.
Điều tuyệt vời là bạn có thể thực hiện hai truy vấn trong một hàm. Vì thế, bài viết kết hợp hai yêu cầu bằng một biểu tượng | ở giữa:
=importxml("https://en.wikipedia.org/wiki/List_of_T_postal_codes_of_Canada", "//td/span/a[1] | //td/b[1]")
Tuy nhiên, bạn sẽ không nhận được cùng kết quả trước đó. Nó sẽ xen kẽ toàn bộ yêu cầu kết hợp vào một danh sách dài, thay vì hai cột. Nó có nhiều lợi ích nhưng không cần thiết ở bài viết này.
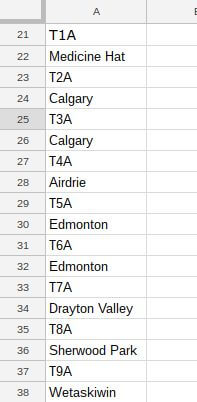
Để chọn mã bưu chính trong các box chứa liên kết ‘Edmonton’. Chúng ta sẽ dùng mã này:
=importxml("https://en.wikipedia.org/wiki/List_of_T_postal_codes_of_Canada", "//td[span/a='Edmonton']/b[1]")
Đặt phần “search” - text đủ điều kiện thu hẹp kết quả trong dấu ngoặc vuông mà không làm ảnh hưởng tới cách thức mang đến kết quả.
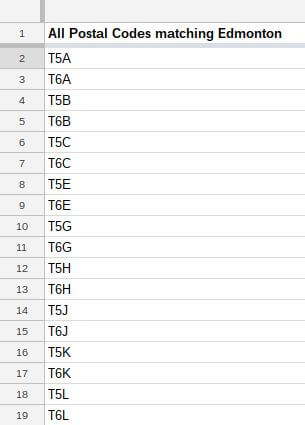
Giờ tới các tên các khu vực lân cận. Viết hàm importXML phù hợp vào cột tiếp theo, lấy text sau từ “Edmonton.”
Bài viết lấy toàn bộ nội dung của span[1] và dùng dấu ngoặc đơn và chéo để phân chia nội dung, đưa “Edmonton” vào cột đầu tiên và tên khu vực lân cận vào cột sau. Sau đó, chúng ta có thể kết hợp mã bưu chính với tên tương ứng:
=importxml("https://en.wikipedia.org/wiki/List_of_T_postal_codes_of_Canada", "//td[span/a='Edmonton']/span[1]")
Tiếp theo, dùng hàm Split và nối một số cột sau đó để chia tách & nhóm dữ liệu đang xử lý:
=SPLIT(concatenate(B2:J2),"(/)")
Cuối cùng, đây là bảng kết quả với thông tin cần thiết:
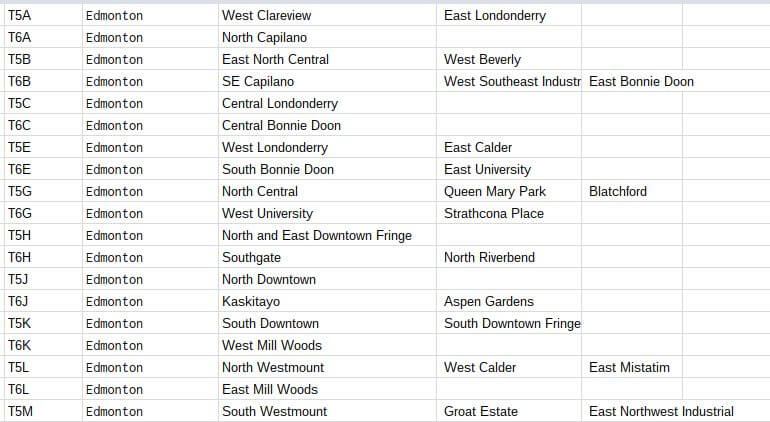
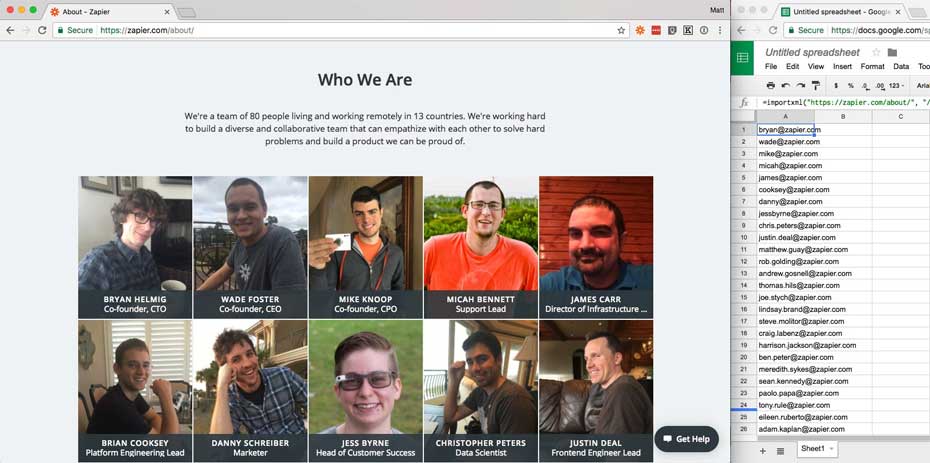
Bài viết sẽ hướng dẫn bạn cách lấy toàn bộ email nhân viên trên trang About | Zapier. Nhìn vào mã nguồn, bạn sẽ thấy mọi địa chỉ email của từng thành viên đều nằm trong trường class=”email”. Khi muốn chỉ định một thuộc tính tag, dùng hàm ImportXML của Google Sheets như sau:
=importxml("https://zapier.com/about//", "//span[@class='email']")
Để lấy các địa chỉ Zapier bằng cách dùng “sức mạnh” của Regex, chúng ta sẽ nhập lệnh <span> thay vì tìm class. Giờ chúng ta sẽ thực hiện nhiệm vụ này trong hai bước: Gọi thông tin từ trang Zapier vào cột đầu tiên, sau đó, phân loại email vào cột thứ hai:
=importxml("https://zapier.com/about//", "//span")
=regexextract(A1, "[a-zA-Z0-9_\.\+-]+@[a-zA-Z0-9-\.]+\.[a-zA-Z0-9-]{2,15}")
Cuối cùng, chúng ta sẽ có bảng này:
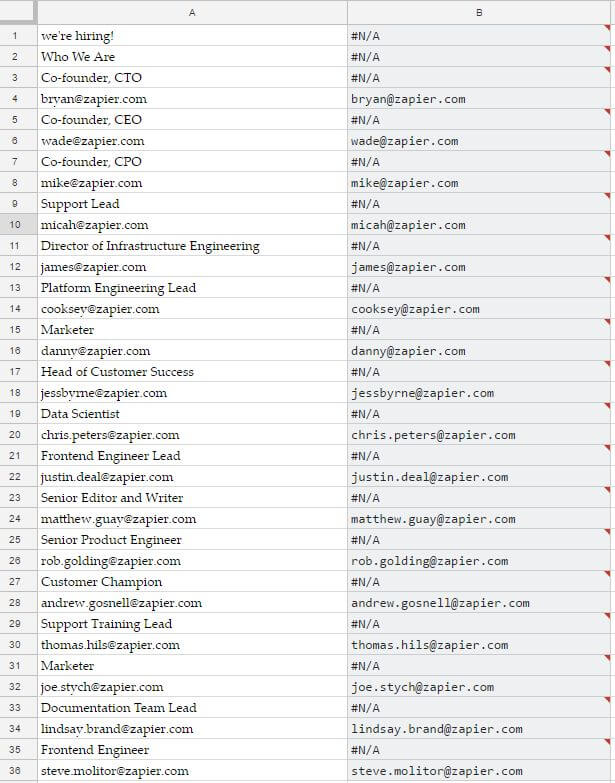
Nhớ rằng, ImportXML sẽ tự điền vào tất cả các cột và hàng tùy thuộc vào dữ liệu nó tìm thấy. Truy vấn regex phải được điền vào từng ô bạn muốn có kết quả. Để kết hợp tất cả lại với nhau, bạn chỉ cần dùng lệnh Regexextract là một công thức hằng số mảng (array):
=ArrayFormula(IFERROR(REGEXEXTRACT(IMPORTXML("https://zapier.com/about//", "//span"), "[a-zA-Z0-9_\.\+-]+@[a-zA-Z0-9-\.]+\.[a-zA-Z0-9-]{2,15}")))
Và đây là kết quả:
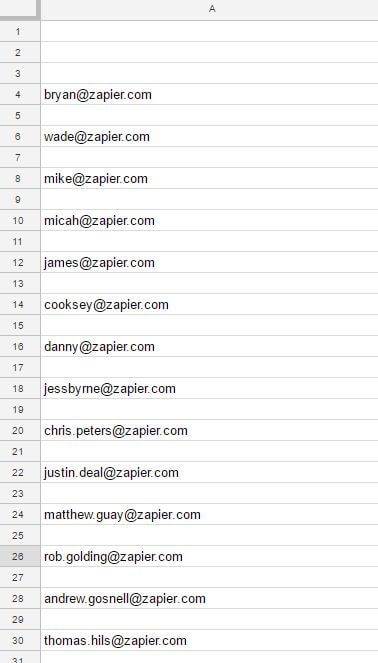
Hi vọng bài viết hữu ích với các bạn!
 Vy Vy
Cập nhật: 24/02/2022
Vy Vy
Cập nhật: 24/02/2022
Theo Nghị định 147/2024/ND-CP, bạn cần xác thực tài khoản trước khi sử dụng tính năng này. Chúng tôi sẽ gửi mã xác thực qua SMS hoặc Zalo tới số điện thoại mà bạn nhập dưới đây:










